- 2025년 4월 30일 오전 6:56
- 조회수: 1151
 김성범 교수님
김성범 교수님
연합학습(federated learning)은 데이터를 중앙 서버로
전송하지 않고, 각 로컬 디바이스(스마트폰, 가전제품 등)에서 독립적으로 학습한 모델 정보(파라미터)만을 활용해 글로벌 모델을 구축하는 학습 방식이다. 이 방식의 핵심은 개별 기기에 저장된 데이터를 중앙(외부)으로 전송하지 않고도 모델을 학습시킬 수 있다는 점에 있다.
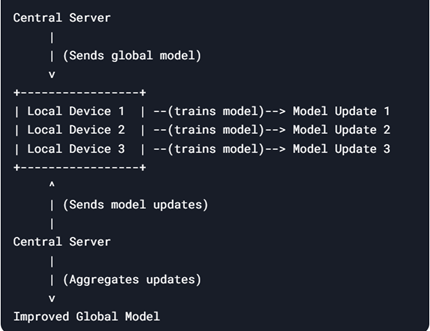
연합학습의 첫 번째 단계는 중앙 서버에서 초기 모델을 생생한 후 이를 각 로컬 디바이스에 배포한다. 이후 각 로컬 디바이스는 자신만의 데이터(사용자건강정보, 금융거래이력, 가전사용패턴 등)를
사용하여 모델을 학습한다. 이 단계에서는 원본 로컬 데이터가 해당 디바이스를 벗어나지 않는다. 결과적으로 원본 데이터가 절대 외부로 유출되지 않는다. 로컬 학습이
완료되면, 각 디바이스는 학습 과정에서 생성된 모델의 정보(예를
들어, 뉴럴네트워크 모델의 가중치와 같은 파라미터)를 중앙
서버에 전송한다. 이때 로컬 디바이스 모델 학습에 사용된 데이터가 전송되는 것이 아니라 학습 결과인
모델 정보만이 전송되므로 데이터 유출 위험이 근본적으로 차단된다. 중앙 서버는 각 디바이스에서 올라온
모델 정보를 통합하여 하나의 글로벌 모델을 생성한다. 이 과정에서는 통계적 기법이나 최적화 알고리즘을
활용하여 각 디바이스의 학습 결과를 반영한다. 가장 기본적인 통합 방법으로는 각 로컬 디바이스의 가중치를
평균 내어 업그레이드된 글로벌 모델을 생성하는 방식이다. 이렇게 개선된 글로벌 모델은 다시 각 로컬
디바이스에 배포되고, 새로운 로컬 데이터를 바탕으로 재 학습된다. 이러한
단계를 반복적으로 수행하면서 모델의 성능이 점진적으로 개선된다.
연합학습의 가장 큰 장점은 데이터 보안을 보장한다는 점이다. 데이터가
로컬 디바이스에만 저장되고, 중앙 서버로는 모델 정보만이 전송되므로 민감한 로컬 데이터가 외부로 노출되지
않는다. 이러한 특성은 의료, 금융, 제조 데이터처럼 유출에 민감한 정보를 다룰 때 특히 유용하다
또한, 연합학습은 네트워크 효율성을 높이는 데 기여한다. 로컬의 원본 데이터를 대량으로 전송할 필요가 없으므로 네트워크 대역폭 사용량이 감소하고, 전력이 제한된 환경에서도 효과적으로 작동할 수 있기 때문이다. 이는
대규모 데이터 전송이 어려운 환경에서 연합학습의 유용성을 더욱 부각시킨다
종합적으로, 연합학습은 중앙서버에서 글로벌 모델을 유지하면서도 각 로컬 디바이스에 있는 데이터를 활용한 개인화된 학습을 가능하게 한다. 이는 사용자의 특성에 맞춘 서비스를 제공하는 동시에, 전 세계적으로 다양한 데이터를 활용하여 모델의 보편성과 성능을 유지할 수 있다.
Federated learning is a learning method that
builds a global model using only the model information (parameters) learned
independently on each local device (smartphone, home appliance, etc.) without
sending data to a central server. The key to this method is that the data
stored on individual devices can be trained without sending it to a central
(external) location.
The first step in federated learning is to train
an initial model on a central server and then distribute it to each local
device. Each local device then trains the model using its own data (user health
information, financial transaction history, home appliance usage patterns, etc.
At this stage, the original local data never leaves the device. Once the local
training is complete, each device sends the model information (e.g., parameters
such as the weights of the neural network model) to the central server. The
data used to train the local device model is not transmitted, only the model
information that is the result of the training, essentially eliminating the
risk of data leakage. The central server integrates the model information from
each device to create a single global model. This process uses statistical
techniques or optimisation algorithms to reflect the learning results of each
device. The most basic integration method is to average the weights of each
local device to create an upgraded global model. This improved global model is
then deployed to each local device and retrained again based on new local data.
By iterating through these steps, the performance of the model is incrementally
improved.
The biggest advantage of federated learning is
that it ensures data security. Because data is stored only on the local device
and only model information is sent to the central server, no sensitive local
data is exposed to the outside world. This is especially useful when dealing
with security sensitive information such as healthcare, financial, and
manufacturing data.
In addition, federated learning contributes to
network efficiency. By eliminating the need to transfer large amounts of local
source data, it reduces network bandwidth usage and can operate effectively in
power-limited environments. This makes federated learning more useful in
environments where large data transfers are difficult.
Overall, federated learning enables personalised learning using data on each local device while maintaining a global model on a central server. This enables services to be tailored to the user's characteristics, while maintaining the universality and performance of the model by leveraging data from around the world.