- With 현대모비스
- 2023-03-13 ~ 2023-11-27
본 프로젝트의 목표는 PLM(Product Lifecycle Management) 시스템에서 분산된 정보를 효율적으로 통합하기 위해 문서들 간의 연관성을 분석하는 데이터 기반 연관성 알고리즘을 구축하는 것이다. 이를 위해 먼저 사용자 쿼리와 시스템 내 문서 데이터의 유사성을 계산하고, 이를 바탕으로 연관성 그래프를 생성하는 텍스트 데이터 기반 알고리즘을 개발하였다.
한국어 데이터로 사전학습된 BERT 기반의 KLUE-RoBERTa 모델을 차량 도메인의 특성을 고려하여 재학습시켜 사용자 쿼리와 시스템 내 문서 데이터의 표현 벡터를 추출하였다. 그 후에는 코사인 유사도와 TF-IDF를 이용하여 텍스트 데이터의 표현 벡터 간 유사성을 계산하고, 이를 가중합하여 쿼리와 문서 간의 유사도를 정의하였다. 이를 통해 쿼리와 유사한 문서를 찾아 추천함으로써 연관성이 높은 문서를 탐색할 수 있게되었다. 또한 각 소과제의 특성에 따라 알고리즘을 적용한 결과를 분석하여 유관 문서가 추출되었음을 정성적으로 검증하였다.
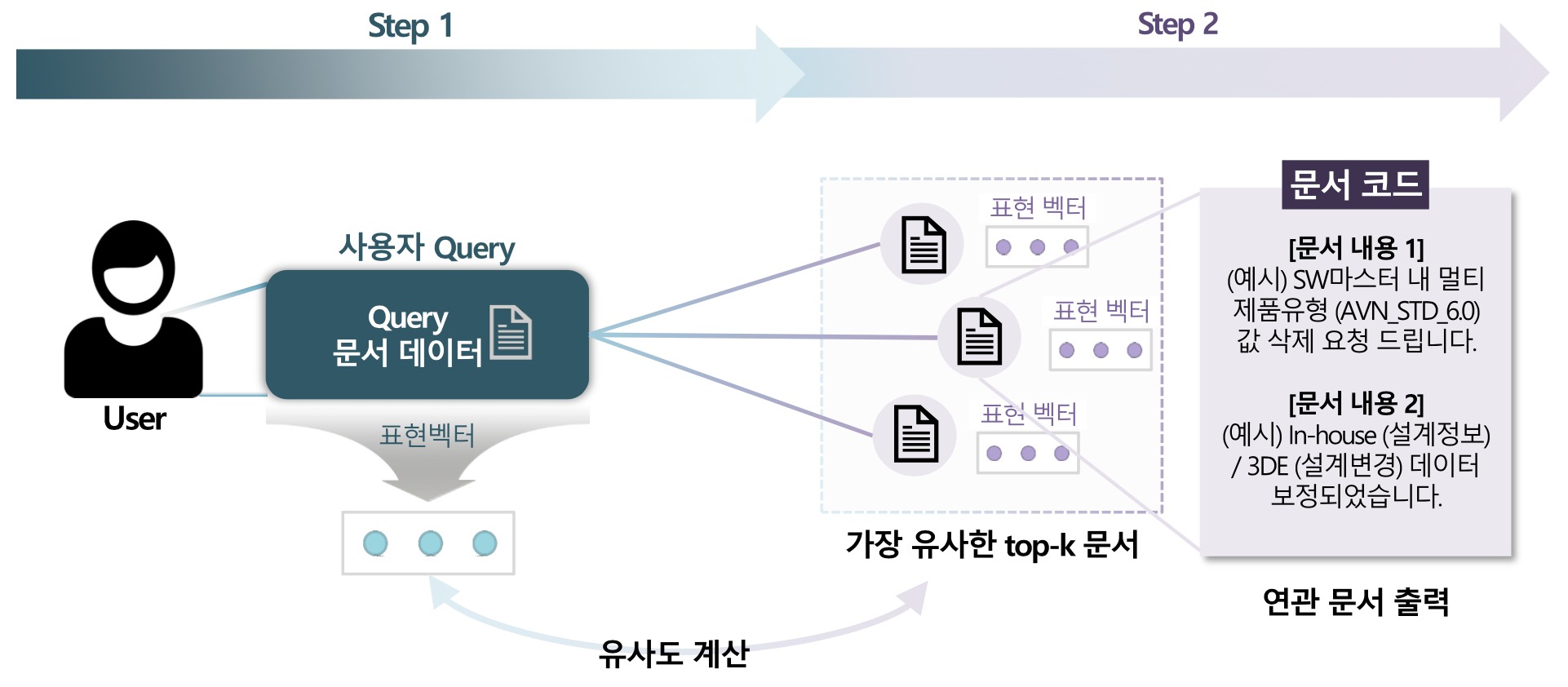
1. 연관 아이디어 추천
쿼리와 유사한 아이디어 문서를 다양하게 탐색할 수 있도록 연관문서 출력 단계를 확장하였다. 먼저, 쿼리와 유사성이 높은 문서를 1단계 연관 문서로 분류하고, 이러한 문서들과 유사성을 보이는 문서들을 2단계 연관 문서로 정의하여 관계성을 보다 체계적으로 구성하였다.
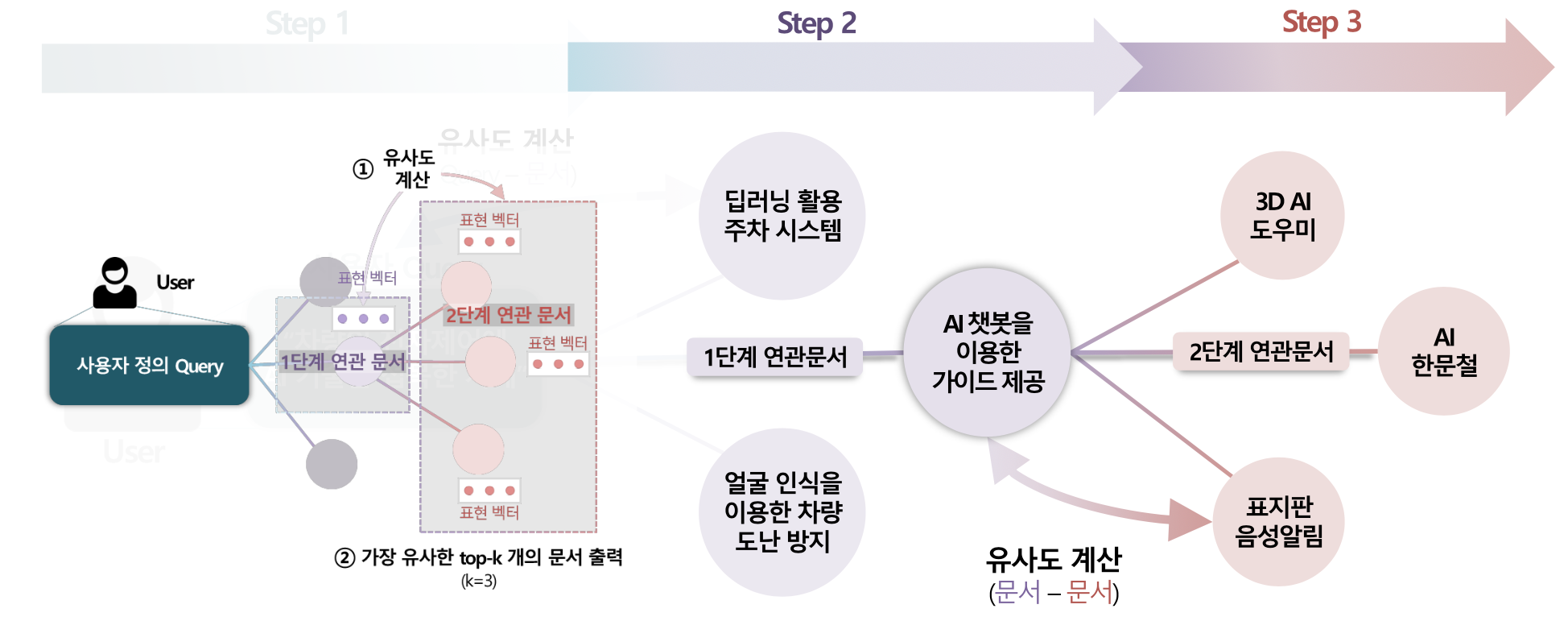
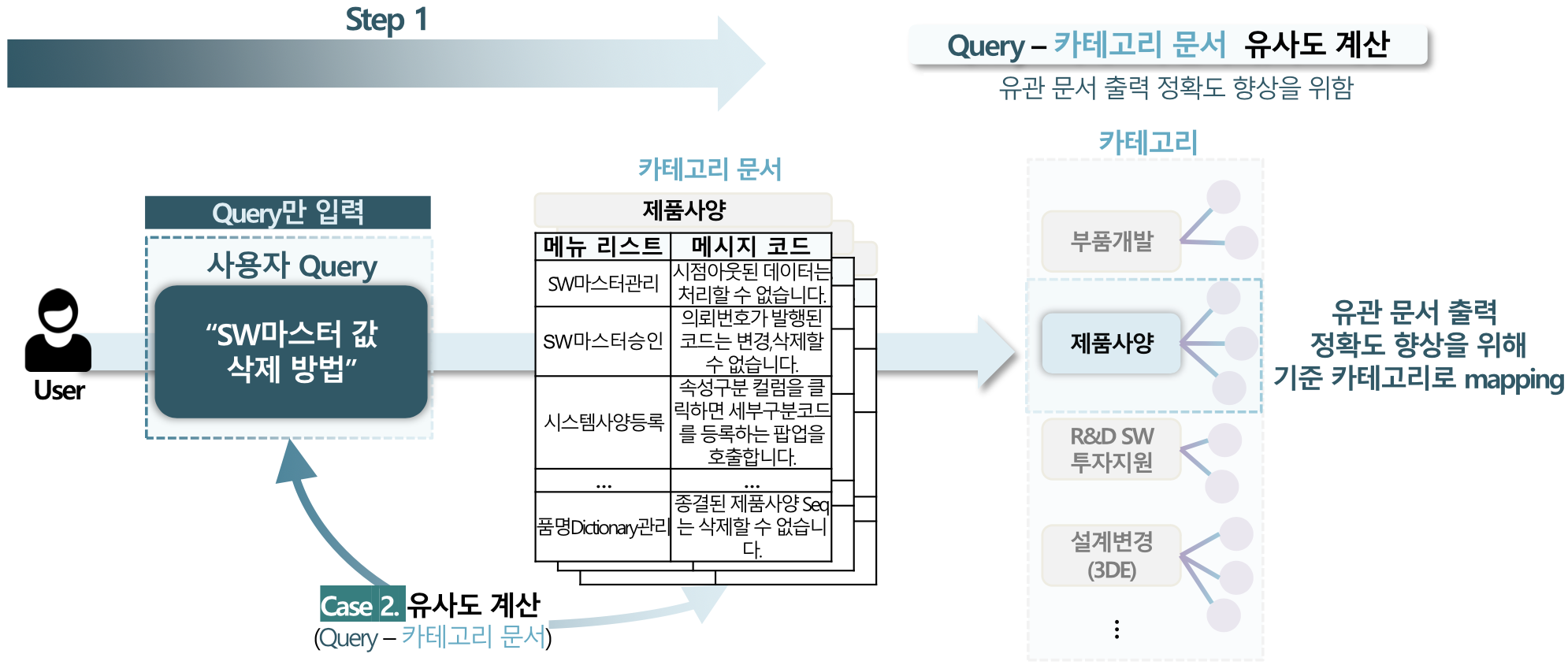
2. 연관 문제상황 및 해결 방법 자동 조합 및 추천
ITSM(IT Service Management) 문서 내에서 쿼리와 관련된 요청 내용에 대한 관련 해결 방안 및 담당자를 제안하도록 구성하였다. 유관 문서의 출력 정확도를 높이기 위해 카테고리를 매핑하여 특정 카테고리 내에서 쿼리와 가장 유사한 연관 문서를 출력한다. 또한, 쿼리와 함께 카테고리가 제안되지 않은 경우에는 카테고리를 예측하는 알고리즘을 추가하였다.
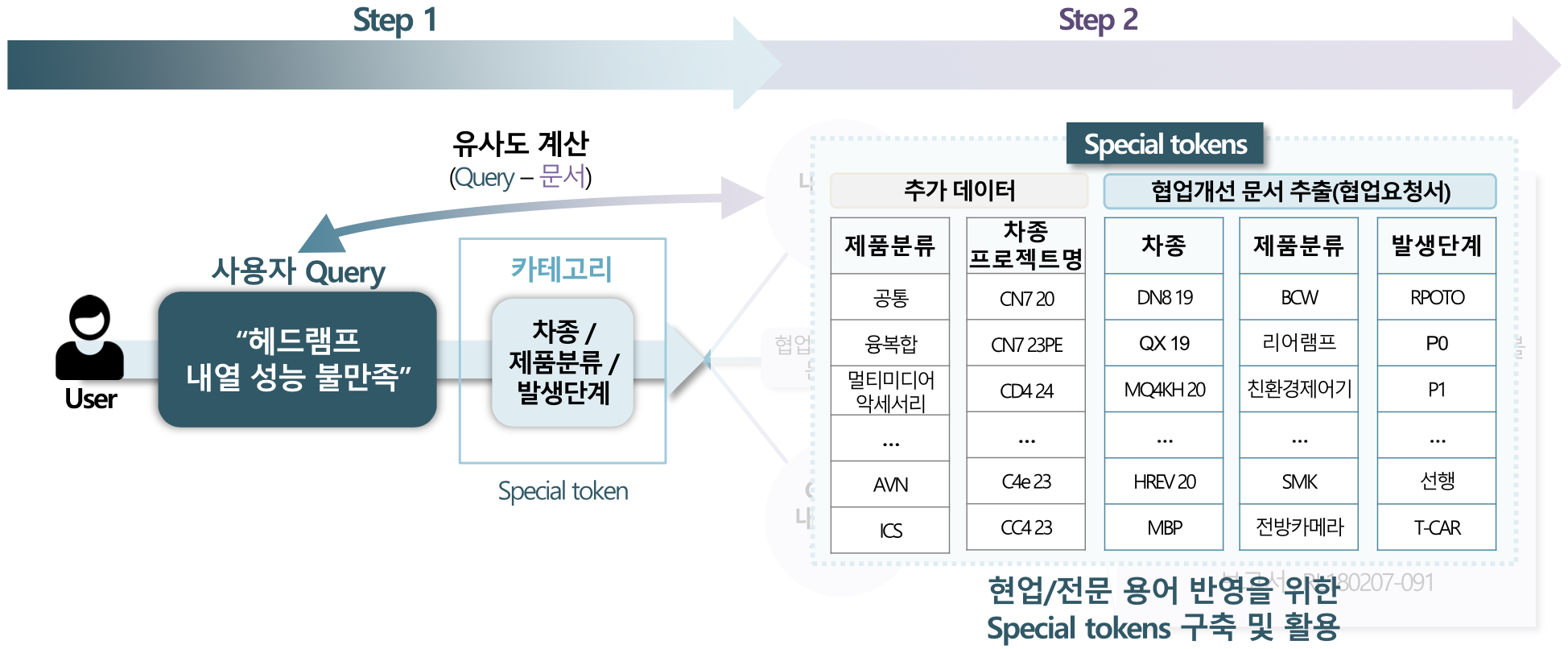
3. 연관 문제상황 기반 유관 문서 추천
협업 요청서 문서 내에서 쿼리와 관련된 제기 내용에 대한 해결 방안을 제안하기 위해 구성하였다. 추가적으로 협업 시스템 데이터의 특성을 반영하기 위해 전문 용어 스페셜 토큰들을 구축하고 활용하여 쿼리와 관련된 문서를 추천한다.