- With 삼성전자 CSE팀
- 2022-07-01 ~ 2023-06-30
본 프로젝트의 목표는 반도체 공정 이력 기반 데이터를 통해서 제품 특성값 예측 및 효율적인 공정관리를 하기 위한 불확실성 인과 관계 모델을 구축하는 것이다. 예측에 영향을 미치는 주요 공정에 대한 해석 및 불확실성을 정량화하는 것이 핵심이며, 반도체 공정 이력 데이터에 존재하는 시계열성 및 공정 간 순차 정보를 반영하여 반도체 제품 특성값 예측을 수행하였다. 입력데이터의 분포가 시간에 따라 변할 수 있는 covariate shift 및 출력데이터인 제품 특성값이 다양하게 존재할 수 있는 multi-output 문제를 모델 학습에 반영하여 불확실성 인과 관계 모델을 고도화하였다.
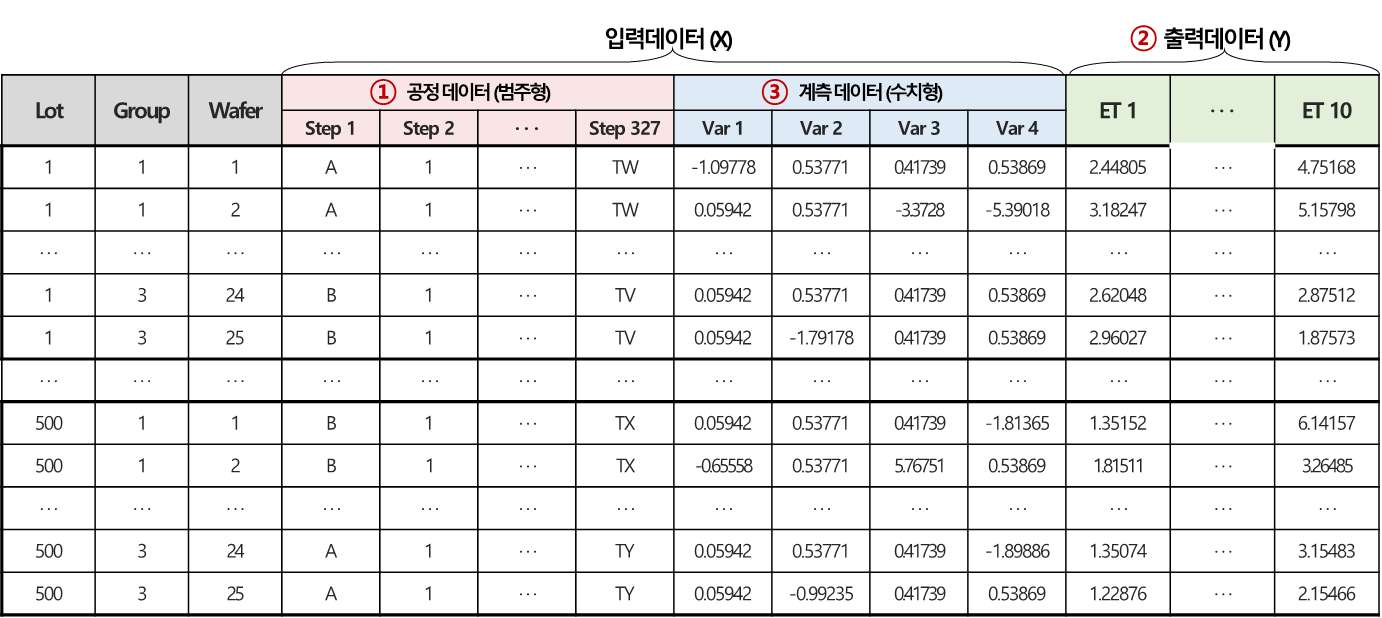
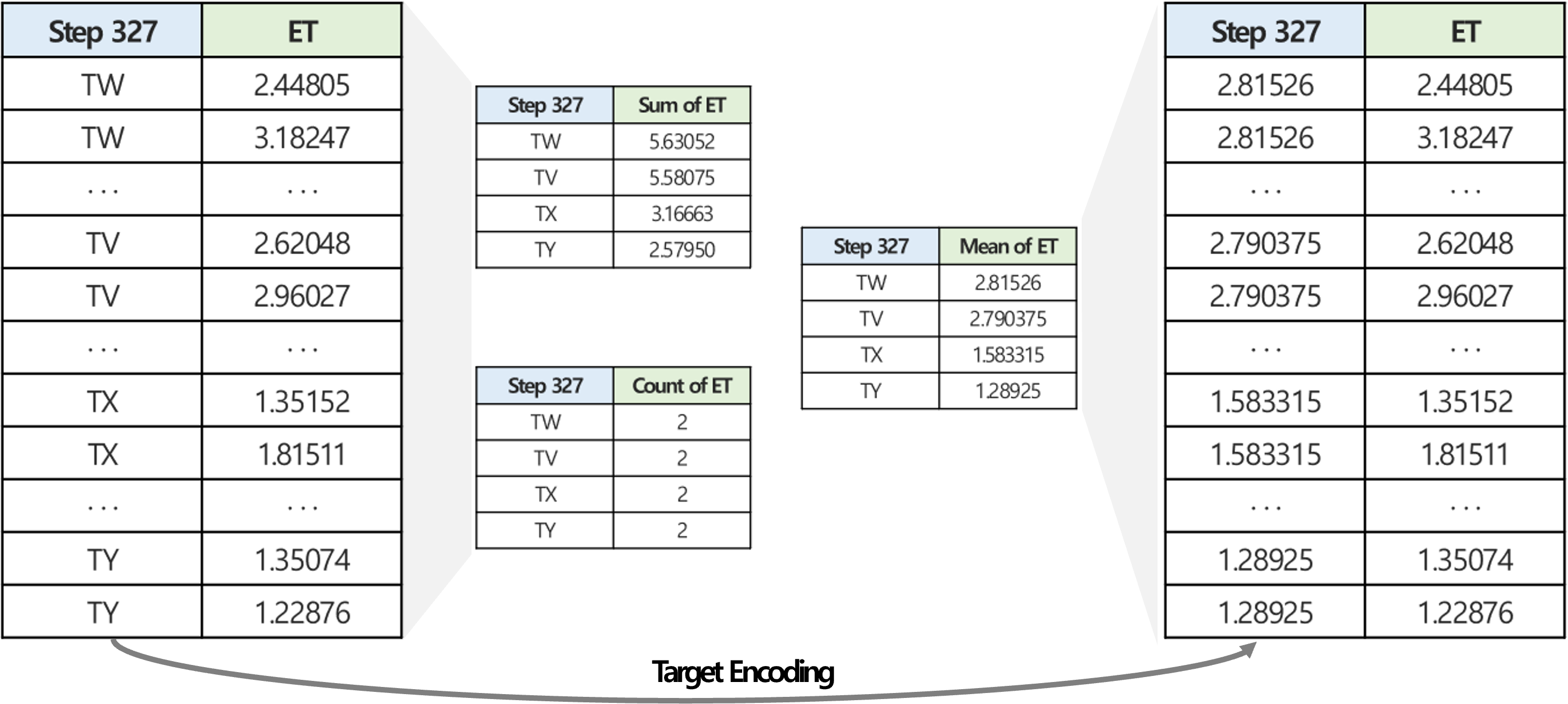
1. 반도체 공정 이력 기반 데이터 탐색 및 전처리
반도체 공정 이력 기반의 시계열 데이터에는 범주형으로 구성된 공정 step 정보와 수치형 계측 데이터가 혼재되어 있으므로 각 데이터 타입별 적절한 전처리가 요구되며, 예측 알고리즘에 적용하기 위해 데이터 특성을 반영한 정제 과정이 필요하다. 이에 따라 주어진 데이터에 대한 데이터 탐색 및 전처리를 진행하였다.
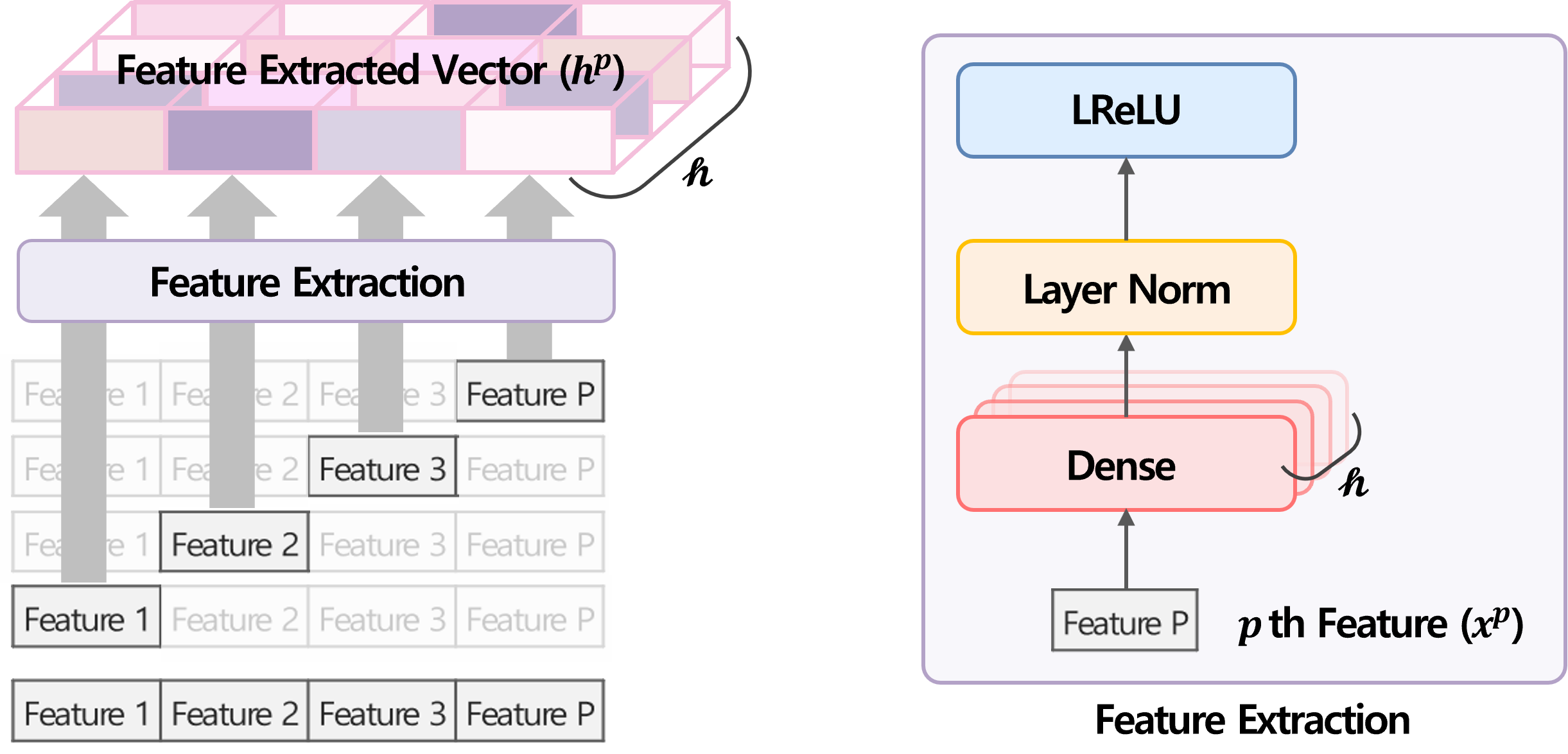
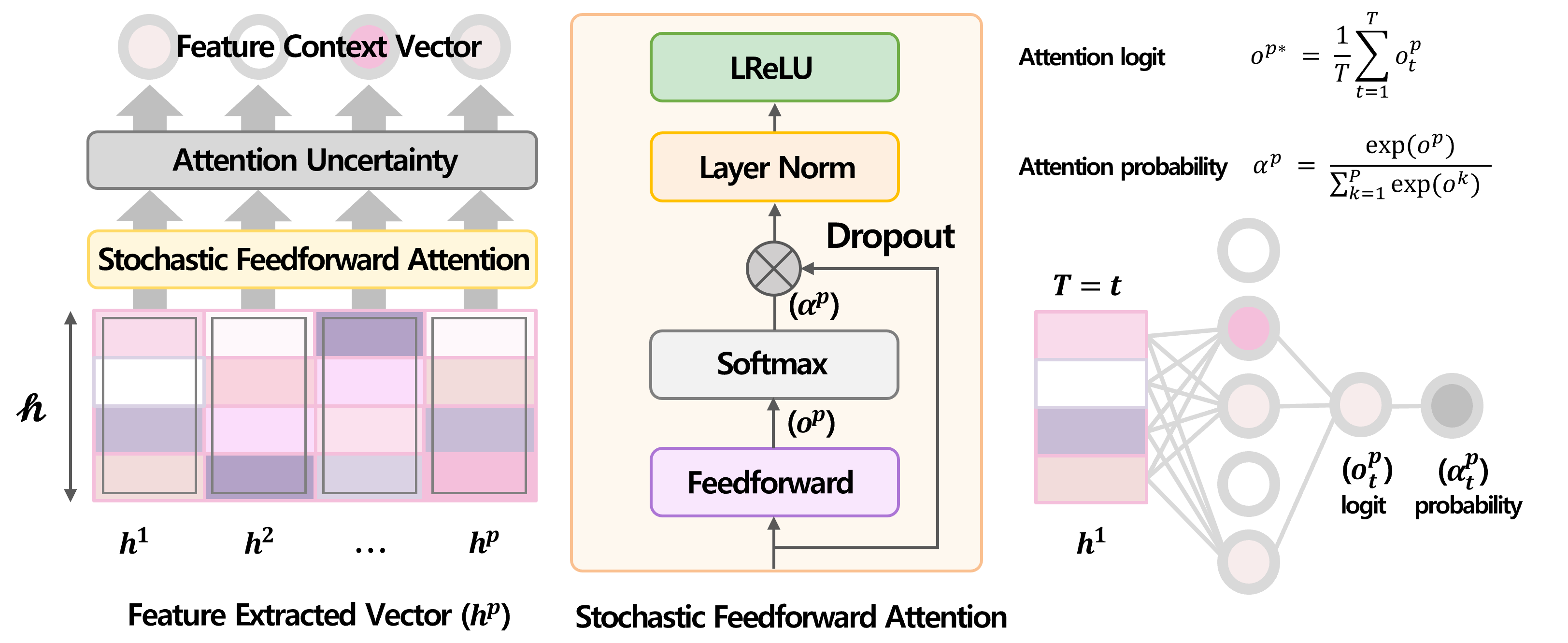
2. 순차적 공정 데이터 특징을 반영한 해석 가능한 알고리즘 개발 및 불확실성 정량화
공정 이력 데이터에는 각 공정 별 순차성이 존재한다. 본 프로젝트에서는 순차성을 반영하면서 동시에 결과에 대한 주요 공정 해석이 가능한 알고리즘을 제안하였다. 예측값과 입력값 사이의 관계 파악을 위해 모델에 내부적인 파라미터로 모델을 구성(model specific)하는 방식인 Attention mechanism을 활용하여 변수별 주요 해석이 가능하도록 모델을 구축하였다. 모델 구조에 stochastic feedforward attention layer를 사용하여 해석에 대한 불확실성 정량화가 가능하도록 하였다.
3. 시점에 따라 데이터 분포가 변경되는 상황 반영
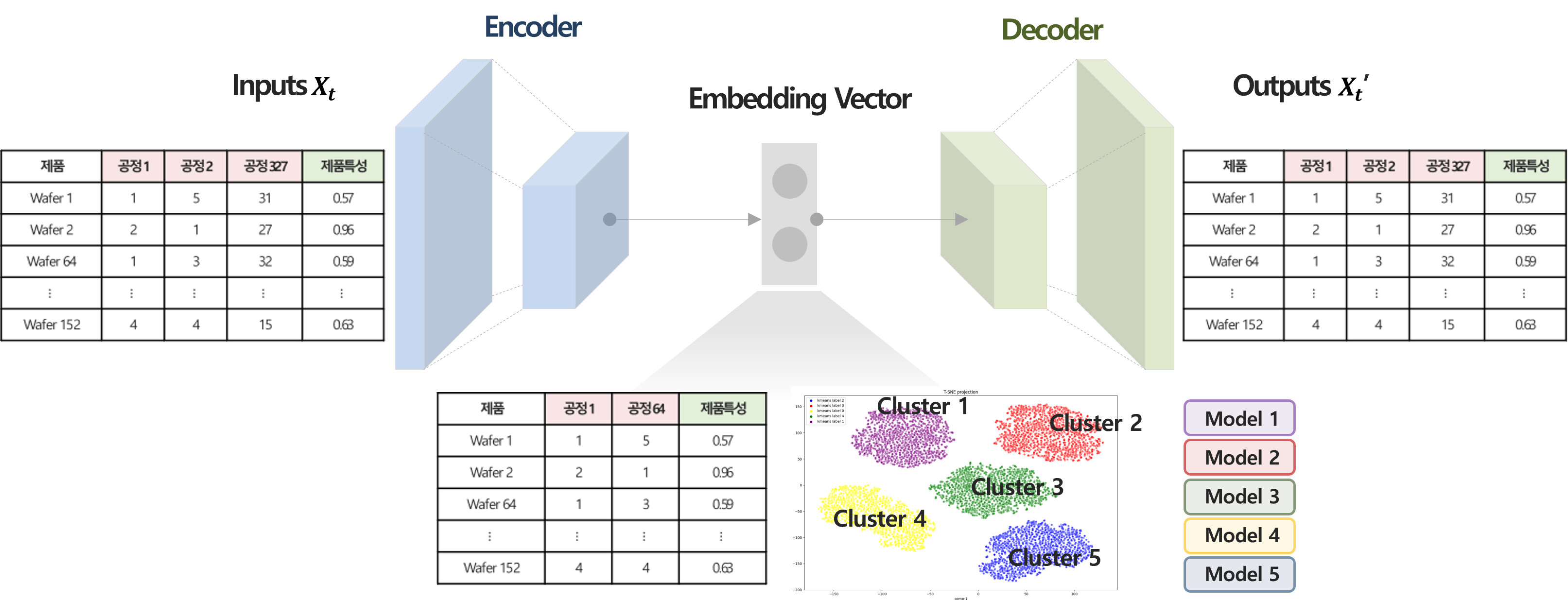
공정 데이터는 시점에 따라 데이터 분포가 변화하는 특성을 지니기 때문에, 이를 고려하여 cluster를 사전에 정의하고 각 cluster별로 모델 학습 및 검증을하는 2단계 모델링을 수행하였다. 본 프로젝트에서는 각 cluster별로 결과를 도출한 2단계 모델링 기법을 시점을 반영하지 않은 결과와 비교하여 성능 평가를 하였다.
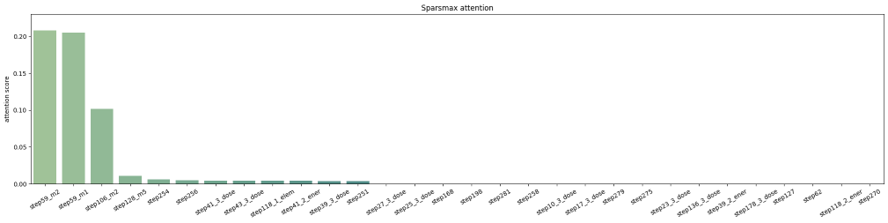
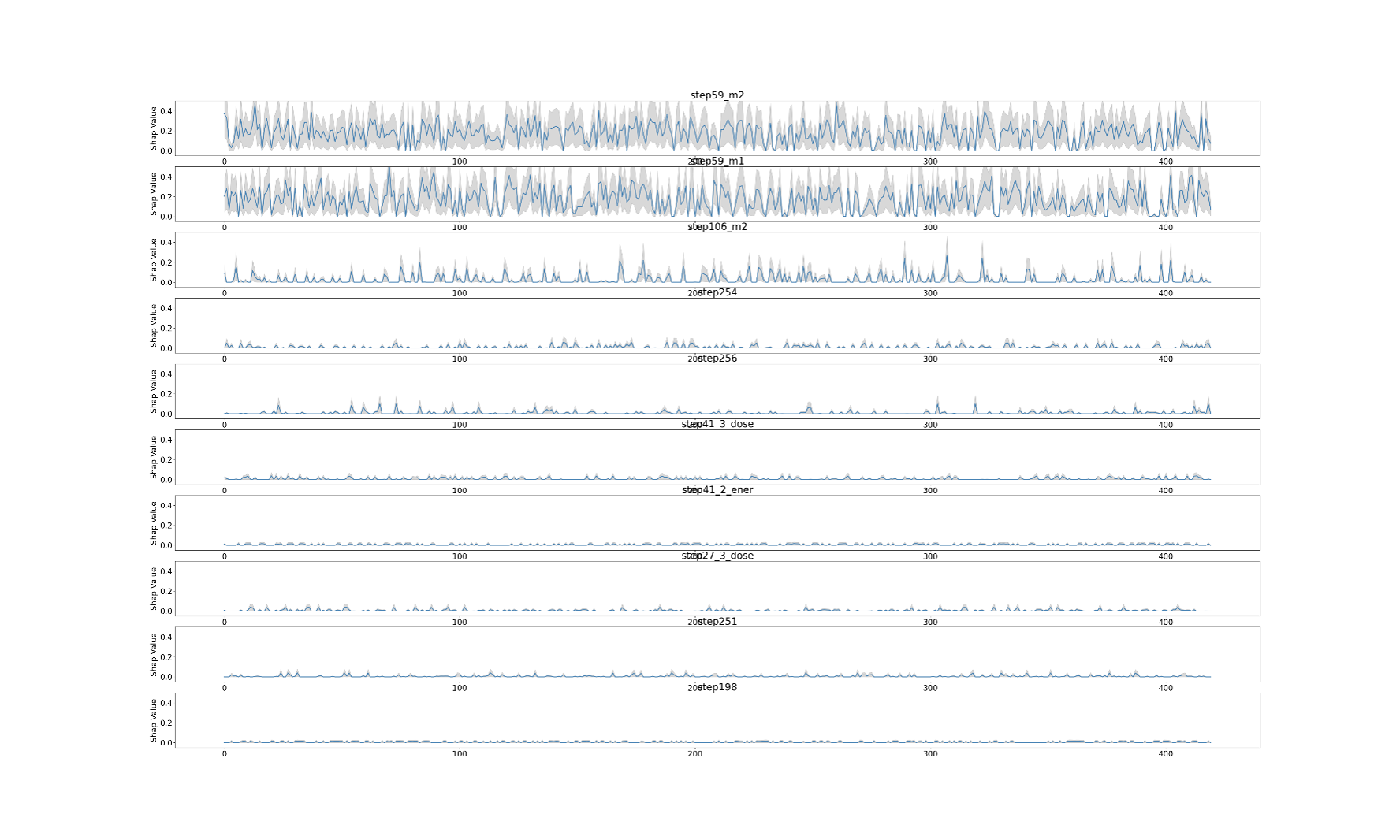
4. 예측 알고리즘 주요 변수 해석 및 불확실성 정량화 시각화 결과
아래 그래프는 공정 이력 데이터에 대한 주요 변수 해석 및 불확실성 정량화를 시각화한 것이다. 첫 번째 그래프는 주요 변수 해석에 대한 그래프이다. X축이 각 공정 변수들이며 Y축 값이 attention score이다. 제품 특성값 예측에 있어서 주요하게 영향을 준 변수를 확인할 수 있다. 두 번째 그래프는 주요하게 영향을 준 변수 상위 10개에 대한 불확실성 정량화 값이다. 제품 특성값 예측 결과에 대한 주요 변수 해석 및 불확실성을 확인할 수 있다.